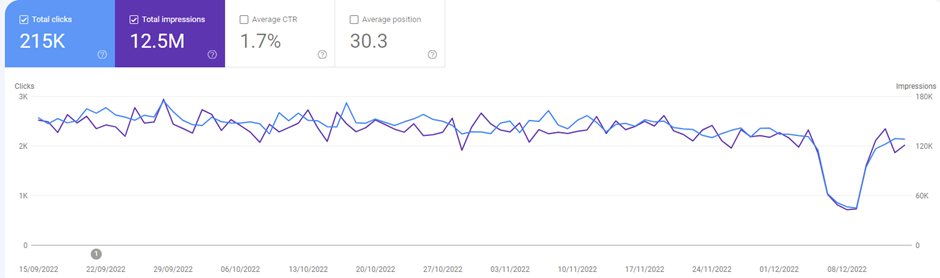
It was just after 12 noon on a weekend, when an email came in from one of our biggest SEO clients. Its title said Urgent Help. It was about one of their sites which we don’t handle.
“Dear Elad and Yonit,” it started, “we have a major issue with one of our sites starting December 6. Google suddenly deindexed most of the pages on the site and the homepage appears on the SERP without any meta data, which leads to drops in rankings and clicks. We have no idea what happened, might it be related to the December algorithm update? Would you be able to assist?”
Well.
We love nothing more than a challenge.
Step 1: Find the Problem
Even though we weren’t handling the specific site for the client in that point of time, we had in the past, so we knew it very well. We analyzed it before and worked on it with brilliant results, including achieving top 3 results on major, competitive keywords in Google USA.
We had Google Search Console access and we had previously used external tools to scan it as well.
First thing, we wanted to make sure there wasn’t any penalty, manual or otherwise, for the site. GSC has not indicated anything like that.
Secondly, we rechecked the SERP. The homepage was indeed still indexed and ranked, but returned no meta data (title or description) on the SERP:
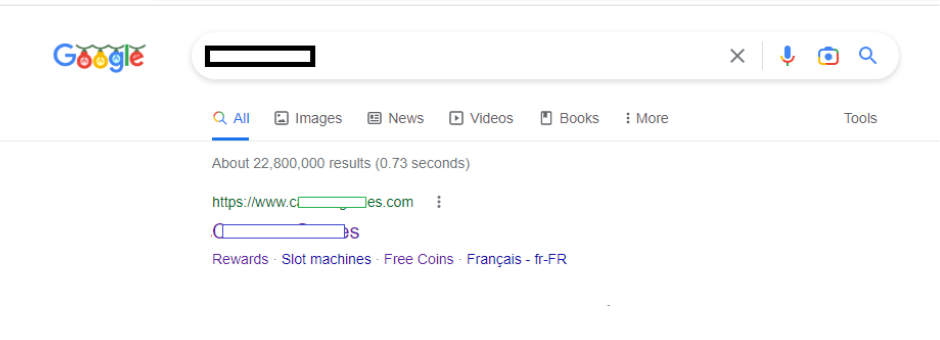
No title? No meta description? Deindexed inner pages? This strongly suggests Google can’t read the page correctly.
The site itself was loading correctly, so we did 2 things in parallel:
One, we tried to scan it with external tools. Screaming Frog, Ahrefs and even Xenu all got stuck after trying to scan the homepage. They, too, couldn’t read anything.
It wasn’t a robots.txt file issue. We checked, it was implemented correctly and allowed crawlers access.
Two, we checked Google Search Console for a Live Test.
And the result?
Google saw a blank page… or didn’t see anything at all?!
We checked the code.
<script async="" type="text/javascript" src="/TSPD/[here there was a long number]?type=10"></script>
<noscript>Please enable JavaScript to view the page content.<br/>Your support ID is: 12xxxxxxxxxxxx58.</noscript>
</head><body>
</body></html>Nothing on the <body> part, and an odd script just before the ending of the <head>.
We might have found the culprit.
Step 2: Verify with the Client’s Dev Team
Once we had a suspect, we delivered it to the client.
“Can the developers please advise on this script line,” we asked.
“The developers can’t even see it,” they answered.
It wasn’t in the source code, because the site by itself was loading successfully, I explained, but crawlers are bumping into it.
After a few hours they finally managed to find it. It was supposed to be a security script somebody installed without checking, and yes, it blocked the crawlers that couldn’t get passed it.
They immediately removed it.
Step 3: Back to Life
Once the dev team removed the script, the client’s in-house team started reindexing the site. It took not more than a few hours for Google to reindex everything properly, and presented the site correctly on the SERP.
And the traffic?